
안녕하세요.
이번 포스트에선 데이터의 시각화 등을 위해 사용되는 대표적인 차원 축소 방법인 PCA에 대해 다뤄보겠습니다.
뜬금 없이 PCA에 대한 내용이 나와서, 약간 서순이 안맞는다 느낄 수 있지만 .. 모두 다 리뷰할 예정입니다 ..
거두절미하고 어려운 내용은 최대한 제외한 시각적인 자료로 설명할 예정이니 찬찬히 읽어보는 것을 추천드립니다!
분산이란?
PCA를 다루기 이전에, 가장 먼저 다뤄볼 개념은 데이터의 퍼진 정도를 의미하는 분산입니다.

X축을 기준으로 쭉 펴진 1차원 데이터를 분석할 때, 가장 먼저 눈에 들어오는건 데이터가 퍼진 정도일겁니다.
기초적인 통계 정보지만 PCA에선, 이렇게 데이터가 퍼진 정도를 가장 기본으로 합니다.
이처럼 분산이라는 것은 데이터가 퍼진 정도를 나타내고, 위의 이미지처럼 표현된다라고 이해해주시면 됩니다.
다만 PCA에선 1차원 데이터의 분산이 아닌, 2차원 이상의 데이터의 분산을 활용하게 됩니다.
이러한 분산을 공분산이라고 하며 다음 파트에서 다뤄볼 주요 내용입니다.
공분산이란?
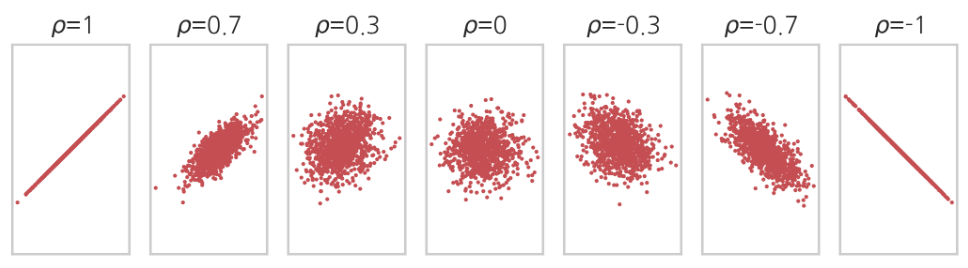
공분산의 개념을 다루는 자료에서, 위와 같은 이미지를 가장 많이 보았을 것이라 생각됩니다.
공분산은 변수 간의 상관관계를 나타내고, 형태에 따라 양 혹은 음의 상관관계를 나타낸다! 라고 말입니다.
상관관계는 잠깐 뒤로 넘겨두고, 일단 공"분산"이라는 말에 집중해보겠습니다.
앞서 우리는 분산에 대해 짚고 넘어갔습니다. 이 때의 분산이라는 것은 결국 데이터가 퍼진 정도를 의미했습니다.
공분산도 결국 2차원 이상의 변수들에 대해 각각의 변수들이 각각의 평균에서 얼마나 퍼져있나를 의미합니다.
다만 퍼져있는 정도와 함께 변수 사이의 관계는 어떤가? 를 함께 보게되며 이를 변수 사이의 관계라고 합니다.
이때의 관계라는 것은 서로 비례하거나, 반비례하는 변수 사이의 변화 관계를 의미합니다.
이렇게 각각의 변수의 퍼진 정도와 관계를 기반으로 행렬로 나타낸 것을 공분산 행렬이라고 정의합니다.
이렇게 구해진 공분산 행렬로는 어떤 것을 알 수 있을지 다음 파트에서 다뤄보도록 하겠습니다.
고유값 분해 (Eigen Value Decomposition)
앞서 우리는 분산과 공분산에 대해서 배워보았고, 어느 정도 이해할 수 있었습니다.
이 때 PCA에선, 공분산 행렬을 분해하기 위해 고유값 분해라는 방법을 사용하게 됩니다.
고유값 분해란 어떤 정방 행렬을 값(크기)과 벡터(방향)으로 분해하는 방법을 의미합니다.

복잡해 보이지만, 조금 풀어서 본다면 고유 값과 고유 벡터의 의미는 다음과 같습니다.
고유벡터는 선형 변환 후에도 방향이 바뀌지 않는 벡터입니다.
고유값은 선형 변환 후 벡터의 크기가 얼마나 커지거나 작아지는지를 나타내는 값입니다.
고유 벡터라는 말이 어렵게 보일 수 있지만 결국엔 그냥 벡터이고, 우리가 배웠다시피 벡터는 방향을 갖습니다.
그렇다는건? 고유값 분해란 어떤 행렬을 상수배(고유 값)와 벡터(고유 벡터)로 나타내는 것을 의미합니다.
이러한 고유값 분해(크기와 방향으로 분해)와 공분산(데이터가 퍼진 정도)을 겹쳐서 생각해보자면?

앞선 공분산 행렬을 분해해서, 데이터가 각각 어느 방향으로 얼마나 퍼져있나~를 보는 것이라 할 수 있습니다.
물론 많은 부분들이 생략되어있지만, 어느 정도 이해하실 수 있을 것이라 생각합니다.
다음 파트에선, 구해진 고유 값과 고유 벡터를 통해 차원 축소를 수행하는 과정을 다뤄보겠습니다.
내 데이터에 대한 차원 축소
앞서 공분산과 고유값 분해를 다루며 약간 어지러울 수 있지만, PCA의 설명에 대해선 거의 다 끝났습니다!
앞서 배운 개념을 예제 데이터를 통해 공분산 행렬과 고유값 분해를 거치며 차원이 어떻게 변화하는지 보겠습니다.
# 1. 데이터 생성 (2차원 데이터)
X = np.random.randn(100, 5) # (100, 5) shape
# 2. 데이터 정규화
X_mean = np.mean(X, axis=0)
X_normalized = X - X_mean
# 3. 공분산 행렬 계산
cov_matrix = np.cov(X_normalized.T) # (5, 5) shape
# 4. 고유값과 고유벡터 계산
eigenvalues, eigenvectors = np.linalg.eig(cov_matrix) # Value : (5), Vector : (5, 5)
일반적인 학습 데이터처럼 100개의 데이터와 5개의 특성이 있다고 가정하겠습니다.
이러한 데이터에 대해 공분산 행렬을 계산했을 땐, 자기자신을 포함해서 여러 특성과의 관계를 행렬로 나타냅니다.
5개의 특성이 존재하기에, 전체 공분산 행렬은 정방 행렬의 형태인 (5, 5) 형태로 나타나게 됩니다.
이 공분산 행렬의 대각 행렬은 자기 자신과의 관계를 나타내기에, 전부 1의 값이 도출되게 됩니다.
이러한 공분산 행렬을 분해했을 땐, 5개의 고유 값과 5개의 고유 벡터를 얻을 수 있게됩니다.
우리가 PCA를 배우며, 주성분이라는 말을 자주 보았는데 이 5개의 고유 값과 벡터가 바로 성분들입니다.
그리고 그 성분들 중, 고유 값을 기준으로 내림차순 하였을 때, 가장 큰 값의 고유값과 벡터가 바로 주성분입니다.

그리고 Scikit-learn에서 PCA를 사용할 때, 파라미터를 입력하는 과정이 고유값의 개수를 선택하는 과정입니다.
5차원의 데이터를 2차원으로 낮춘다면, 고유값이 작은 뒤쪽의 데이터는 모두 무시하고 앞의 2개만 사용합니다.
# 5. 축소할 차원의 수만큼 고유 벡터를 선택
k = 1
selected_eigenvectors = eigenvectors[:, :k]
# 6. 선택한 고유 벡터(방향)를 기반으로 내 데이터를 투영(Projection)
reduced_data = np.dot(centered_data, selected_eigenvectors)
이를 실제 코드 상에서 본다면? 위와 같은 단계로 아주 짧은 코드로 동작합니다.
다만, 6번 과정에서 고유 값이 큰 고유 벡터의 방향으로 데이터를 투영시킨다는 것은 아래 이미지와 같습니다.

고차원의 데이터를 내가 구한 방향에 맞게, 그 방향을 가리키는 차원으로 전부 투영시켜준다! 입니다.
Zk를 봤을 때, 데이터의 분산을 가장 잘 보존하는 주성분이면서도 방향이 있기에 화살표가 있는 것이 보이실까요?
이렇게 PCA는 공분산과 고유값 분해를 통해 데이터의 분산 구조에서 고유 값(크기)과 고유 벡터(방향)을 구하고
분산이 보존되는 최대의 방향으로 데이터를 모두 투영(행렬곱)하는 과정이다! 라고 정리할 수 있겠습니다.
그런데 .. 축소한 데이터를 버리고 다시 복구하고 싶다면 어떻게 해야하나요? 라는 물음이 생길 수 있습니다.
이는 앞서 활용한 고유 벡터를 전치(Transpose) 시켜, 뒤집어준 다음 다시 행렬곱을 수행해주면 됩니다.
# 7. 역투영(Back-Projection)을 통해 데이터를 복구해보자
reconstructed_data = np.dot(reduced_data, selected_eigenvectors.T)
다만 축소 과정에서 버려진 나머지(5개 중 3개)들이 있기 때문에 그 볼륨정도의 손실은 무조건적으로 존재합니다 ..
그냥 이러한 방식으로 데이터를 복구할 수 있다~ 정도만 이해해주시면 될 것 같습니다.
이렇게 PCA에 대해 90% 이상 모두 다루었습니다! 생각보다 간단하게 이해할 수 있었을거라 생각합니다.
마지막 파트에선 비선형 관계의 데이터에서의 차원 축소 방법을 간단하게만 소개합니다!
비선형 데이터에서의 차원 축소
앞서 우리가 공분산을 통해 변수 사이의 관계를 구할 때, 비례 혹은 반비례라는 말을 사용했었습니다.
이러한 비례 혹은 반비례는 아주 간단한 관계인 선형 관계라는 것을 의미합니다.
하지만 현실 세계의 데이터에서, 선형 관계보단 비선형 관계가 더욱 많다고 할 수 있습니다.
기본적인 PCA의 경우 데이터의 선형성을 기본으로 하기에, 비선형 데이터에선 잘 동작하지 못합니다.
다만, SVM에서 Kernel trick이 사용된 것처럼 PCA에도 비선형을 위한 축소 방법(t-SNE)도 존재합니다.
이번 파트에선 Kernel trick에 대해서만 간단하게 짚고 넘어가도록 하겠습니다.
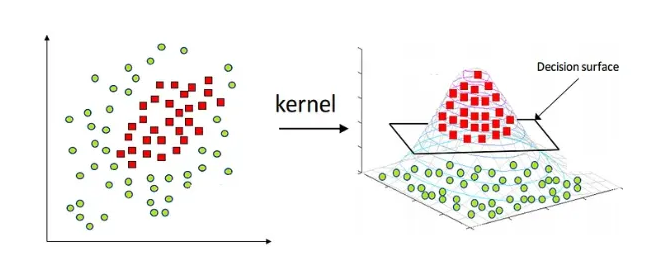
Kernel trick은 데이터를 고차원 공간으로 변환한 후, 그 공간에서 어떠한 처리를 수행하는 방법을 의미합니다.
위 이미지에서 왼쪽의 경우에 선으로 분리하는 것이 불가능하지만, 고차원에선 면으로 분리될 수 있습니다.
다만, 데이터를 직접적으로 고차원에 매핑하는 것이 아닙니다. 그렇게 한다면 너무 느려져 버립니다 ..
그렇기에 Trick이라는 말을 사용하며, 마치 늘어난 차원을 사용하는 것처럼~ 이라는 의미입니다.
이에 대해선 추후에 다시 한번 깊게 리뷰하도록 하겠으며, 이번 PCA에선 여기까지 마무리하도록 하겠습니다.
마치며
여기까지 와서 돌이켜보니, PCA에 대해 어느 정도 쉽게 이해하실 수 있었을까요?
머신러닝을 이해할 땐, 머리 속에서 3차원을 그려놓고 이리저리 돌려가며 이해하는 것이 중요한 것 같습니다.
제가 드린 설명이 부족할 수 있지만 이번 포스트에 이러한 내용이 느껴지셨기를 바랍니다 ..
여기까지! 긴 글 읽어주셔서 감사합니다.
'Machine Learning > Machine Learning' 카테고리의 다른 글
| Support Vector Machine (SVM) (3) | 2024.11.19 |
|---|---|
| 로지스틱 회귀 (Logistic Regression) (4) | 2024.09.03 |
| 선형 회귀 (Linear Regression) (3) | 2024.09.02 |