
이번 포스트에선 머신 러닝의 가장 기본인 선형 회귀에 대해 다뤄보고자 합니다.
로지스틱 회귀와 함께 가장 중요한 개념이라 생각하며, 반드시 이해하고 넘어가야 한다고 생각합니다.
설명이 잘못되었거나, 이해가 어려운 경우 언제든 피드백 부탁드립니다.
선형 회귀란?
어떠한 데이터가 있을 때, 이 데이터를 가장 잘 설명하는 하나의 직선을 찾는 과정을 의미합니다.

이러한 직선을 통해 우리는 새로운 데이터가 입력되었을 때, 값을 대략적으로 추정할 수 있게됩니다.
그렇다면 선형 회귀에서 데이터를 가장 잘 설명하는 하나의 직선이란 무엇일까요?
좋은 직선인지를 알기 위해선 만들어진 직선이 데이터를 얼마나 잘 설명하는지에 대한 점수가 있어야 합니다.
이를 잔차(Residual)라고 하며, 직선과 실제 값 사이의 차이를 의미합니다.
잔차를 통해 우리는 현재 직선이 어떠한지 평가하고, 이를 최소가 되도록 만드는 것을 목표로 합니다.
이러한 평가를 비용 함수 혹은 손실 함수라는 용어로 정의하고, 머신 러닝은 이러한 함수를 기반으로 합니다.
결과적으로 우리는 손실 함수의 값이 최소가 되도록 직선을 지속적으로 변경해나가는 과정을 의미합니다.

이러한 과정을 우리는 모델의 학습이라고 하며, 대표적인 학습 방법으로 경사하강법이 있습니다.
경사하강법은 선형 회귀 모델을 학습시키는 대표적인 방법이며, 딥러닝과 같이 크고 복잡한 모델의 경우엔
이러한 경사하강법을 통해 학습시키는 것이 일반적이면서 최적의 방법이라고 할 수 있습니다.
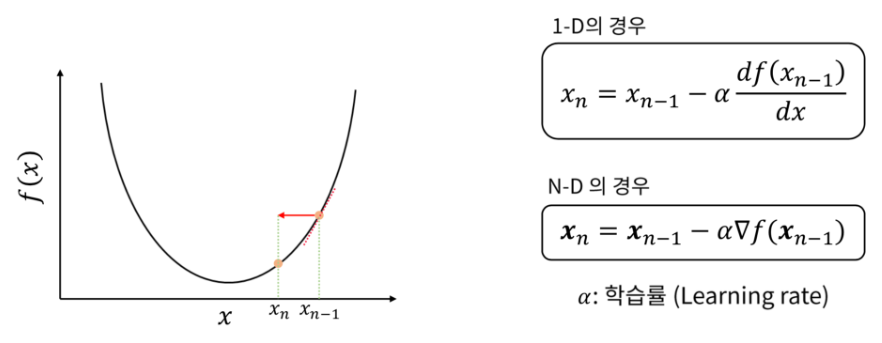
경사하강법은 첫 랜덤 초기화를 시작으로 직선을 통한 오차 계산, 미분, 업데이트를 반복적으로 수행합니다.
이 때의 업데이트는 직선의 방정식에 사용되는 파라미터 W와 b를 업데이트 하는 것을 의미합니다.
우리가 만들 직선이 결국 파라미터 W, b에 의해 결정되기 때문에 이를 업데이트 해주어야하기 때문입니다.
경사하강법은 다음 단계를 통해 파라미터를 점진적으로 업데이트 하며, 손실 함수를 최소화하게 됩니다.
1. 내 데이터의 차원 수 즉, 특성 수에 맞추어 랜덤한 W와 b를 정의한다.
2. 입력 데이터 (x_1 ... x_n)에 대해 W와 내적한 뒤 편향을 더해주어 값을 도출한다.
3. 도출된 값과 실제 정답 사이의 잔차를 측정하고, 이를 MAE, MSE, RMSE와 같은 손실 함수로 오차를 도출한다.
4. 오차를 기반으로 W와 b에 대해 각각 편미분을 진행하여, 파라미터에 대한 기울기를 도출한다.
5. 기울기가 0이 될 때까지 기울기 부호의 반대 방향으로 파라미터를 움직이며, 위의 과정을 반복한다.
이러한 방식으로 최적의 선을 찾아가는 방법을 경사하강법 기반의 선형 회귀라고 합니다.
현재 우리가 사용하는 대부분의 딥러닝은 이러한 경사하강법을 개선하고 고도화하여 사용하고 있습니다.
선형 회귀를 경사하강법 기반으로 학습시킬 수 있지만, 파라미터 W, b를 계산 한번으로 추정할 수도 있습니다.
이는 경사하강법의 모든 단계를 구현하는 대신, 공식을 통해 빠르게 결과를 도출할 수도 있습니다.
또한 경사하강법을 위한 하이퍼 파라미터의 조정같은 번거로운 과정도 없습니다!
이렇게 한번에 파라미터를 추정하는 방법을 정규방정식(Normal Equation) 이라고 합니다.

정규방정식은 위와 같은 형태로 정의되며, 선형대수학 행렬 개념으로 풀이됩니다.
정규방정식을 최대한 간단하게 설명하자면 이렇습니다.
정규방정식이라는 말이 어렵지만, 결국 간단하게 보면 우리가 풀던 방정식이라고 할 수 있습니다.
우리가 풀던 방정식은 좌변 혹은 우변을 정리하면서 우리가 모르는 어떤 미지수를 찾는 과정을 거쳤습니다.
정규방정식 또한 어떤 미지수를 찾는 과정을 의미하며, 이 때의 미지수는 모델의 파라미터를 의미합니다.
입력 데이터 A와 가중치 X, 그리고 그에 대한 정답 B가 있을 때의 식을 행렬로 나타내면 아래와 같습니다.

이러한 행렬 형태를 간단하게 나타내면 다음과 같은 방정식의 형태로 나타낼 수 있습니다.

위의 방정식에서 미지수 X를 알기 위해선, 입력 데이터 A 행렬을 없애주어야 합니다.

행렬을 1로 만들어 제거해주기 위해선, 양 변에 역행렬이라는 행렬을 곱해주어야 합니다.
이는 방정식에서 좌변/우변을 정리하는 것과 같으며 이 때, 양 변에 역행렬을 곱해주는 과정이 필요하게 됩니다.
결과적으로 어떤 행렬과 그에 대한 역행렬의 연산 결과는, 단위행렬이라는 결과가 나오게 됩니다.
이러한 단위 행렬은 행렬 X와 곱했을 때, 행렬 X가 그대로 도출되는 행렬을 의미하며, 1을 곱한 것과 같습니다.

그렇기에 어떤 행렬에, 그 행렬에 대한 역행렬을 곱해주는 식으로 정리할 수 있게됩니다.
하지만 여기서 문제가 한가지 있습니다.
역행렬은 존재할 수 있는 조건이 존재하며, 정사각 행렬에서만 역행렬이 존재할 수 있습니다.
즉, (데이터의 수, 데이터의 특성 수)로 이루어진 대다수의 데이터들은 역행렬이 존재할 수 없게됩니다.

이런 상황에서의 역행렬을 정의할 때, 사용되는 것이 바로 위의 식으로 정의되는 의사역행렬입니다.
이러한 의사역행렬을 사용하여, 역행렬이 없는 경우에도 X를 찾을 수 있게됩니다.

식의 PINV는 pseudo inverse(의사역행렬)을 의미하며, 의사역행렬은 위와 같은 식으로 정의됩니다.

어떤가요? 이 식을 정리했을 때, 위에서 본 정규방정식과 같은 식이 되는 것을 볼 수 있습니다.
이렇게 의사역행렬을 활용한 방법을 정규방정식이라고 하며, 이를 통해 X를 한번에 계산할 수 있게됩니다!
물론 모든 데이터에서 적용할 수 있는 방법은 아니지만, 선형 회귀에 대해선 아주 잘 동작합니다!
선형 회귀와 최소자승법에 대해 조금 더 자세하게 알고싶다면, 아래 글을 참고해주시길 부탁드립니다!
https://darkpgmr.tistory.com/56
최소자승법 이해와 다양한 활용예 (Least Square Method)
한글로 최소자승법 또는 최소제곱법, 영어로는 LSM(Least Square Method) 또는 LMS(Least Mean Square) 방법.최소자승법 하면 흔히 어떤 점들의 분포를 직선이나 곡선으로 근사하는 것만을 생각하기 쉽습니다
darkpgmr.tistory.com
이번 포스트에선 선형 회귀와 함께 관련된 개념들을 알아보았습니다.
포스트에서 등장한 정규방정식과 경사하강법은 파라미터를 추정하는 최소자승법의 방법 중 하나입니다.
헷갈릴만한 개념들이 많이 등장하지만 최대한 쉽고, 제가 이해했던 방법대로 설명을 작성했습니다.
이 외에도 로지스틱 회귀, SVM 등에 대해서도 다뤄보고자 계획 중에 있습니다.
또한 글을 읽어주시며, 혹시라도 이후에 작성되었으면 하는 내용이 있으시다면 남겨주셔도 좋습니다.
긴 글 읽어주셔서 감사합니다.
'Machine Learning > Machine Learning' 카테고리의 다른 글
| Support Vector Machine (SVM) (3) | 2024.11.19 |
|---|---|
| PCA (Principal component analysis, 차원 축소) (4) | 2024.10.08 |
| 로지스틱 회귀 (Logistic Regression) (4) | 2024.09.03 |