
이번 포스트에선 선형 회귀와 함께 근본으로 다루어지는 로지스틱 회귀에 대해 다뤄보고자 합니다.
선형 회귀가 값의 예측, 즉 회귀에 대한 모델이었다면 로지스틱 회귀는 분류에 대한 문제를 해결합니다.
로지스틱 회귀라는 이름이지만, 분류에 사용되는 모델인 것을 명심해주시길 바랍니다.
글을 읽어주시며, 이해가 잘 안되시거나 잘못된 설명이 존재하는 경우 언제든 피드백 부탁드립니다.
로지스틱 회귀(Logistic Regression)란?
선형 회귀와 거의 유사하게 동작하지만, 임의의 입력 데이터의 범주를 구분하기 위해 사용됩니다.
그렇기에 어떤 값이 아닌, 입력 데이터를 기반으로 데이터를 이진 분류를 목적으로 합니다.

왼쪽 이미지와 같이 잘 분리되어있는 2개의 데이터 군집이 있을 때, 이를 Class라고 합니다.
Class 속 데이터들은 이미 어떤 Class에 속해있는지, 정해져있는 상태이고 이를 쉽게 알 수 있습니다.
하지만 오른쪽 이미지와 같이 Class를 알 수 없는 임의의 데이터가 입력된 경우엔 어떨까요?
지금은 2차원이지만 3차원 혹은 4차원과 같이 이해하기 어려운 차원에서 데이터가 입력되면 어떨까요?
이러한 경우에 대해, 데이터를 확률적으로 어떤 범주에 속하는지 분류하는 방법을 로지스틱 회귀라 합니다.
로지스틱 회귀는 앞서 설명한 내용처럼, 선형 회귀와 거의 유사하게 동작하고 있습니다.
이러한 로지스틱 회귀는 어떻게 동작하고 학습되며, 어떠한 출력을 도출하는지 확인해보겠습니다.
로지스틱 회귀(Logistic Regression)와 시그모이드(Sigmoid) 함수

로지스틱 회귀는 기본적으로 선형 회귀와 유사하게 동작합니다.
가중치 벡터와 편향을 통해, 입력 데이터에 대해 내적을 수행하고 이를 통해 값을 도출합니다.
도출된 값은 직선을 기준으로 어느 방향에 존재하고, 어느 정도 떨어져 있는지에 대한 값을 의미합니다.
선형 회귀의 경우엔 이 과정에서 도출된 값과 정답 값을 통해 가중치 벡터와 편향을 업데이트 해주었습니다.
하지만 로지스틱 회귀는 선형 회귀와 다르게 입력 데이터가 어떤 범주에 속하는지 분류해주어야 합니다.
데이터의 범주 구분을 위해선 데이터의 범주를 가장 잘 분리할 수 있는 최적의 결정 경계를 찾아야 합니다.
최적의 결정 경계란, 선형 방법으로 데이터를 가장 잘 구분하는 직선 혹은 초평면을 의미합니다.
그렇다면 현재의 결정 경계가 어느 정도 수준으로 데이터를 구분하는지 어떻게 평가할 수 있을까요?
이에 대해선 조금 나중에 다루고, 먼저 로지스틱 회귀의 핵심에 대해 먼저 다뤄보겠습니다.
앞서 로지스틱 회귀는 선형 회귀와 유사하며, 출력으론 가중치와 내적한 결과를 도출한다고 설명했습니다.
조금 생각해봤을 때, 내적 결과만으로 데이터의 분류와 가중치 업데이트를 모두 수행하기엔 어려울 것 같습니다.
내적 결과의 범위가 얼마나 크고 작을지 알 수 없고, 이를 명확하게 나누는 임계값 또한 매번 달라질 것 같습니다.
이러한 상황에서 값의 범위를 명확하게 제한할 수 있는 효과적인 형태는 무엇일까요?
이 때, 로지스틱 회귀는 위 문제들의 해결을 위해서 입력 데이터를 확률 값으로 변환하여 사용합니다.
예를 들자면, 내일 비 올 확률(비가 온다 or 비가 안온다)이 얼마나 될 것 같아? 음 .. 80% 쯤 될 것 같은데?
정리하자면 로지스틱 회귀는 가중치와의 내적 결과에 추가 연산을 통해 확률 값으로 변환하여 사용합니다.
이 때, 사용되는 추가 연산을 시그모이드(Sidmoid) 함수라고 합니다.

이러한 시그모이드 함수는 어떠한 입력에도 0~1 사이의 확률 형태의 결과를 도출합니다.

또한 시그모이드 함수는 입력되는 값이 매우 크거나 혹은 매우 작은 경우 1 혹은 0에 매우 가깝게 나타나며,
입력 값이 매우 작을 경우, 결정 경계의 근처인 0.5 위아래 사이의 확률을 나타냅니다.
여기까지, 일단 중구난방으로 흩어진 값들을 0에서 1사이의 범위로 모두 가져오는 작업을 거쳤습니다.
하지만 적게는 수백에서 수천, 많으면 수만에서 수십만에 이르는 데이터들을 어떻게 구분할 수 있을까요?
이 때, 확률을 기반으로 데이터를 특정 범주로 구분하는 어떠한 기준을 임계값이라고 정의합니다.
일반적으로 이진 분류에선, 0.5의 임계값을 사용합니다.
0.5를 기준으로 이보다 큰 확률이라면 Positive Class, 작다면 Negative Class로 구분하게 됩니다.
물론 모든 상황에서 0.5의 값을 사용하진 않으며, 도메인에 따라 이 값을 다르게 사용하곤 합니다.
정리해보자면, 우리는 다양한 크기로 이루어진 데이터를 어떤 범위 안으로 모두 정리해주었습니다.
또한 정리된 데이터를 특정 범주로 구분하기 위한 임계값의 정의에 대해서도 알아보았습니다.
다음으론 로지스틱 회귀가 학습되는 과정에 대해 알아보겠습니다.
로지스틱 회귀의 학습 (Feat. 경사하강법, Binary Cross-Entropy)
위에서 이러한 내용을 언급했던 것을 기억하실까요?
> 그렇다면 현재의 결정 경계가 어느 정도 수준으로 데이터를 구분하는지 어떻게 평가할 수 있을까요?
제가 이전에 정리했던 선형 회귀에 대한 내용을 보신 분들이라면 조금 이해가 되실 것입니다.
우리는 현재의 가중치와 편향으로 도출된 결과들이 좋은지 혹은 나쁜지에 대한 점수가 필요합니다.
이를 손실 함수 혹은 비용 함수의 형태로 나타내어, 이를 최소화하는 형태로 학습을 진행해주어야 합니다.
그렇다면 로지스틱 회귀에선, 어떤 손실 함수를 사용해주어야 할까요?
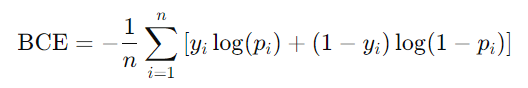
로지스틱 회귀에선 위의 식으로 정의되는, 이진 크로스-엔트로피(Binary Cross-Entropy)를 사용합니다.
입력되는 확률을 기반으로 동작하며, 정답 데이터인 y와 함께 사용됩니다.
여기서 사용되는 Log(p)의 값이 1에 가까운 경우엔 아주 작은 값을, 0에 가까운 경우엔 아주 큰 값을 도출합니다.
또한 입력 데이터의 레이블인 y에 따라, 앞의 항이 지워지거나 뒤의 항이 지워지며 계산되게 됩니다.
예를 들어, y = 1의 경우엔 ylog(p)의 항만 존재하게 되며, y = 0의 경우엔 (1 - y)log(1-p)의 항만 존재하게 됩니다.
이러한 BCE도 손실 함수로써, 전체 손실이 작을수록 좋은 모델이라고 할 수 있게됩니다.
또한 전체 손실이 작아지기 위해선 y = 1의 경우엔 높은 확률을, y = 0의 경우엔 낮은 확률을 가져야 합니다.
> Log(p)의 값이 1에 가까운 경우엔 아주 작은 값을, 0에 가까운 경우엔 아주 큰 값을 도출.
이렇게 도출된 손실을 기준으로 가중치를 업데이트하는 과정은 선형 회귀와 동일합니다.

손실 함수의 값을 기준으로 각 파라미터마다 편미분을 수행한 후, 도출된 기울기를 기반으로 업데이트를 수행합니다.
기울기의 반대 방향으로, 즉 기울기가 0이 되는 순간까지 반복적으로 파라미터를 업데이트하게 됩니다.
이러한 반복적인 파라미터 추정 과정을 경사하강법이라고 합니다.
선형 회귀 및 로지스틱 회귀뿐만아니라, 대부분의 머신러닝과 딥러닝에서 이러한 경사하강법을 사용합니다.
위의 내용들을 정리했을 때, 로지스틱 회귀는 확률을 기반으로 손실을 도출하고, 경사하강법을 통해 학습됩니다.
정리해보니 로지스틱 회귀는 선형 회귀와 동작부터 학습 과정까지 매우 닮아있는 것을 알 수 있습니다.
추가적으로 이러한 분류 모델을 평가하는 방법 또한 존재하며, 이에 대해선 아래 글을 참고해주시길 바랍니다.
https://jeongsae.tistory.com/5
Confusion Matrix, ROC Curve 평가 지표란?
Confusion Matrix 평가 지표는 특정 범주를 구분하도록 학습된 분류 모델의 예측 성능 평가를 위해 사용됩니다. 분류 모델의 예측 성능에 대해 정답/오답의 형태로도 표현할 순 있지만, 이는 데이터
jeongsae.tistory.com
이제 어느정도 로지스틱 회귀에 대해 이해가 되셨을 것이라 생각됩니다.
이번 포스트에선 로지스틱 회귀와 함께 관련된 개념들을 알아보았습니다.
앞서 정리한 선형 회귀와 닮아 있는 부분이 많아, 어렵지 않게 이해할 수 있을 것이라 생각됩니다.
만약 손실 함수를 구하는 부분이 명확하게 이해되지 않는다면, 데이터를 통해 손으로 계산해보는 것을 추천드립니다.
긴 글 읽어주셔서 감사합니다.
'Machine Learning > Machine Learning' 카테고리의 다른 글
| Support Vector Machine (SVM) (3) | 2024.11.19 |
|---|---|
| PCA (Principal component analysis, 차원 축소) (4) | 2024.10.08 |
| 선형 회귀 (Linear Regression) (3) | 2024.09.02 |