
Computer Vision, 영상 처리를 공부하며 RANSAC 이란 개념에 대해 처음 알게 되었습니다.
개념을 접한 글은 2013년도에 작성되어 있었으며, 제가 몰랐을 뿐 매우 유명하고 잘 알려진 개념인 것 같습니다.
이번 포스트에선 이러한 RANSAC에 대해, 어떠한 개념인지 공부한 내용을 정리해보도록 하겠습니다.
RANSAC과 최소자승법
RANSAC은 최소자승법과 같이 데이터를 근사시키는 방법으로 최소자승법의 단점을 보완한 방법입니다.
최소자승법은 일반적인 데이터 (약간의 노이즈를 포함한)에서 훌륭하게 데이터를 근사할 수 있습니다.
하지만 일반적이지 않은 즉, 심각한 이상치가 데이터에 존재하는 경우엔 완전히 잘못된 형태로 근사하게 됩니다.
이는 최소자승법의 특성으로, 모든 데이터에 대해 오차가 적어지는 방향으로 근사시키기 때문입니다.


위 데이터에 대해 우리가 원하는 모델은 좌측의 모델이지만, 최소자승법은 우측과 같이 모델을 추정합니다.
이러한 상황에서 RANSAC을 사용하여 모델을 추정하는 경우, 우리가 원하는 좌측과 같이 모델을 추정하게 됩니다.
RANSAC이 어떠한 방식으로 동작하기에, 좌측과 같이 모델을 추정할 수 있는걸까요?
RANSAC의 모델 추정
RANSAC에서 RANSA는 Random Sample, C는 Consensus를 의미합니다.
Random Sample을 기반으로, Consensus가 최대가 되는 모델을 추정하는 방법을 의미합니다.
이 때의 Consensus란 어떠한 결정(추정된 모델)에 대해 동의(데이터들의)를 받다라는 의미로 사용됩니다.
SVR의 Margin을 예시로 들어, 추정한 모델과 Margin 내에 데이터가 많으면 많을수록 좋은 모델이 됩니다.
모델을 추정하는 과정에서 Random Sample을 통해 모델을 추정하는 방법을 RANSAC이라 합니다.
적은 수의 Random Sample을 통해 반복적으로 모델을 추정하기에, 노이즈에 강건하다고 할 수 있습니다.
RANSAC은 다음 단계를 통해, Consensus가 최대인 모델을 추정합니다.
1. 전체 데이터 중 N개의 데이터를 Random으로 추출
2. N개의 데이터를 통해, 모델을 추정
3. 추정된 모델과 전체 데이터 사이의 Consensus를 계산 ( 모델에 가까이 있는 inlier 데이터의 수 )
4. 위의 과정을 반복적으로 수행하여, 모델 별 Consensus를 계산
5. 반복이 모두 종료된 이후, Consensus가 최대인 모델(파라미터)을 반환
위 과정을 통해 우리는 노이즈가 포함된 데이터를 잘 근사하는 모델을 추정할 수 있게됩니다.
어느 정도 이해가 되긴 했는데, 어떤 데이터가 inlier인지, outlier인지 어떻게 판별하여 계산할 수 있을까요?
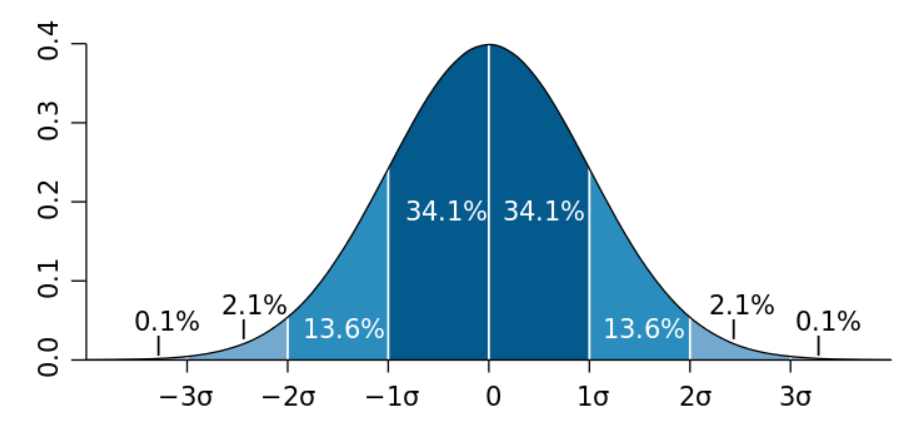
데이터의 이상을 탐지하는 방법 중, 통계 정보를 기반으로 한 3-시그마라는 방법이 있습니다.
내가 가진 데이터들이 갖는 Residual이 정규 분포를 따른다고 했을 때, 이에 따라 in/out lier를 정의합니다.
2-시그마의 경우 약 95.4%의 데이터를 inlier로, 3-시그마의 경우 약 99.7%의 데이터를 inlier로 정의합니다.
정리해보자면, Residual의 분산 혹은 표준편차를 구한 뒤, 이 값이 전체 Residual의 분산 혹은 표준편차의
-2배 ~ 2배 혹은 -3배 ~ 3배 값 범위 안에 있는 경우 이를 inlier로 정의한다고 할 수 있습니다.
이러한 파라미터를 T라고 하며, RANSAC이 갖는 매우 중요한 파라미터 중 하나입니다.
T 값에 따라 알고리즘의 성능이 하락하거나, 오히려 너무 불안정해질 수 있어 세심한 튜닝이 필요합니다.
하지만 모든 상황에서 위의 경우를 적용할 수 있는건 아닙니다.
데이터의 분산이 지속적으로 변화하는 상황에선, 적절한 T 값을 계산하기 어려울 수 있습니다.
이러한 문제를 Adaptive Threshold 문제라고 하며, RANSAC은 현재까지도 꾸준히 연구되고 있습니다.
> 2023년 기준 Adaptive RANSAC에 대해 검색해보았을 때, 이에 대한 최신 논문이 존재하고 있었습니다.
일부 노이즈가 심한 데이터에 대해 적용할 수 있는 방법이지만, 불안한 부분 또한 존재합니다.
알고리즘 자체가 Random Sample을 기반으로 하기에, 시도할 때 마다의 추정 모델이 다릅니다.
또한 수학적 확률이 높다고 하여도, 수렴을 하지 못하는 경우가 존재할 수 있습니다.


위 이미지는 동일한 데이터에서 반복적으로 추정을 시도했을 때의 결과물입니다.
항상 왼쪽의 결과처럼 동작하지 않고, 몇몇 케이스의 경우 원치 않는 방식으로 모델이 추정되기도 합니다.
RANSAC의 장점과 이러한 문제점을 함께 인지하고 사용하는 것이 중요할 것이라 생각됩니다.
RANSAC 활용 예시

Feature Matching과 같은 작업에서 RANSAC을 사용할 수 있습니다.
위의 경우에선 Inlier를 정의하기 위해, 사전 Matching을 통해 매칭된 점들을 정의합니다.
앞선 매칭을 통해 정의된 호모그래피의 경우, 틀린 매칭으로 인해 제대로 된 결과가 나오지 않을 수 있습니다.
그렇기에 RANSAC을 통해, 전체 포인트를 모두 사용하지 않고 랜덤 포인트를 사용하는 방식으로
호모그래피를 정의하여 노이즈에 강건한 Feature Matching을 수행하는 방향으로 진행하게 됩니다.

실제 OpenCV 예제에서도, 이러한 이유로 인해 RANSAC 인자를 사용하고 있음을 알 수 있습니다.
오늘은 RANSAC에 대해 다뤄보았습니다.
RANSAC 방법은 위에서 다룬 Feature Matching 이외에도 다양하게 사용되고 있는 중요한 개념입니다.
딥러닝을 잘 알고 다루는 것도 중요하지만, Computer Vision 방법들도 매우 중요하다고 생각합니다.
이번 포스트를 시작으로, Computer Vision과 관련된 내용들을 하나씩 다뤄보고자 합니다.
혹여라도, 틀린 내용 및 잘못된 설명이 있는 경우 피드백을 부탁 드립니다.
감사합니다.
'Computer Vision' 카테고리의 다른 글
| Haar Cascade Detector (6) | 2024.09.16 |
|---|---|
| Mean Shift, Histogram Backprojection 기반의 Object Tracking (5) | 2024.08.28 |